SnappyData既是个存储引擎,也是个计算引擎。这篇文章主要针对SnappyData的核心组件与整体架构进行讲解,并涉及数据模型、数据注入流程、如何响应SQL请求、集群角色和集群管理等内容
核心组件
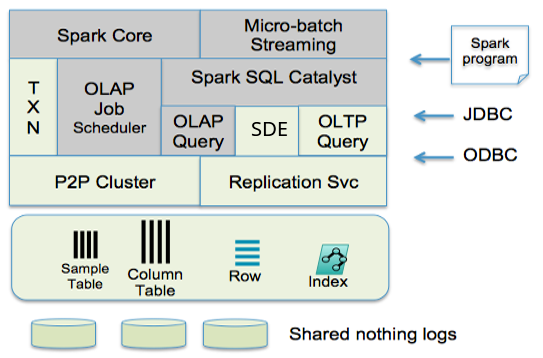
SnappyData融合了GemFire与Spark,其中,图中灰色背景的来源于Spark中的组件。
说存储
SnappyData中的数据既可以采用行存,也可以设计为列存。行存可以设置分区和全局复制(各个节点中都有一份),列存仅仅支持分区(基于hash)。
不管是行存还是列存,数据都是在内存中进行存储的,且可以设置1个或多个副本。内存中既可以使用on heap,也可以使用off-heap(只有企业版才支持)。
如果采用行存,那么内存的消耗势必会更多些,但是它很适合随机DML或者基于点的select查询等OLTP操作。如果采用列表,那么数据会被存储在连续的内存中并进行压缩。
其中列存是从Spark RDD中派生而来,遵循着Spark DataSource的访问模型,并且允许压缩。其压缩算法采用的是游程编码(RLE)和字典编码的方式。
具体来说,就是对于整形的数据,会根据RLE进行压缩,对于String类型的数据,则会采用字典编码进行压缩。
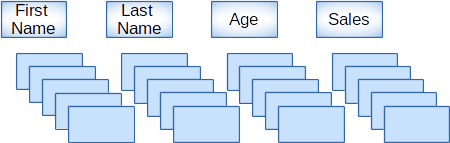
而行存则可以创建索引,支持对于主键与索引字段的快速读写。一般情况下,行表的访问都是通过主键完成,通过对key进行hash运算,很快可以访问到其内存中的地址。
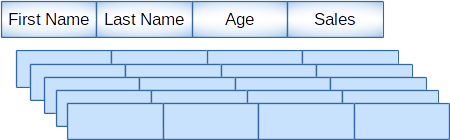
通常,设计行表用于OLTP事务操作,而设计列表的目的主要用于OLAP分析。
关于行表和列表的DDL语句,可以参考官方文档:SQL Reference Guide。
列表
列表有个区别于Spark RDD的显著特点:可变性。即可以对SnappyData中的列表进行点更新或者批量更新等DML操作,这是因为GemFire的作用。
通常批量的update和批量的insert效率会更高,例如执行一个包含10万条数据的update语句,比10万个只包含1条数据的update语句效率要高的多。
列表主要由2个组件组成:
1 | 1、delta row buffer |
首先,delta row buffer是一个行存,它具有与其列表相同的分区策略,它的特点是高速写入。
当数据写入到列表时,它在内部的写入步骤如下:
1 | 1、数据首先会被写入到这个高速的row buffer中 |
其次,delta row buffer中的delta,体现在它的内部结构上。它实际上是一个合并队列。所谓合并的含义,是指对同一列数据进行多个操作,它只会保留最终的状态。
举例来说,假如对某个记录先进行insert或者update操作,在row buffer被刷到列表前,又进行delete操作,那么实际上这个数据会从这个队列中直接删除;又或者某个列上进行连续2个update操作,那么这个row buffer最终只会将最后的那个update的值写入到列表中。
最后,SnappyData还扩展了Spark的Catalyst,使得在列表上进行select操作时,会将delta row buffer中的数据merge到列表中,以保证查询到最新的数据。
同时,对于同一列上多个并发的DML操作,SnappyData采用了copy-on-write来保证数据一致性。
DDL的扩展
由于融合了GemFire和Spark,因此在创建表时,SnappyData对标准DDL语句进行了扩展,具体如下:
1 | 1、COLOCATE_WITH:COLOCATE_WITH {exist_table}语法的含义是对于新建的表,与exist_table具有相同的分区键,且相同键存储在同一个节点上,即数据存储本地化。这样做的好处是当2个表发生基于key的join时,那些非常耗资源的hash join就不用跨节点进行数据传输(广播),而是在本地进行join。这个设计思路非常像关系型数据库Oracle中的cluster存储。这种数据存储本地化的特点,也是SnappyData在做join时比Spark快很多的原因之一。 |
除此之外,列表上也有些限制,例如不能设置主键、唯一约束、索引、不适合过期设置,LRUCount的驱逐不适合,READ_COMMITTED和REPEATABLE_READ的隔离级别不适合列表。
API及其他组件
SnappyData中支持2种API:
1 | 1、标准SQL+Spark SQL |
我们可以把SnappyData当做一个SQL数据库,Spark SQL Catalyst会解析SQL,生成可执行的物理执行计划并代码生成Spark的job去执行。但是,并不是所有的SQL语句都交给Spark去解析。对于行表上快速的点update这种OLTP操作,会由P2P网络负责,同时直接追加到列表上的点insert操作,也会交给GemFire处理,这样做的目的不用通过Spark Job执行,加快执行速度。
P2P(peer-to-peer)网络组件的作用有3个:
1 | 1、发现服务:检测新成员的加入或member失败。 |
客户端可以通过JDBC或ODBC(企业版才支持)连接到SnappyData。除此之外,流处理功能则依赖Spark Streaming组件实现。
SDE是Synopsis Data Engine的简称,核心要素是通过分层采样等方法对超大规模的历史数据建立采样表,通过允许丢失一定比例的准确性,达到快速返回结果的目的。这也是流处理概念的核心:在准确性和低延迟之间做的一种取舍。这种方法也叫AQP(approximate query processing),即近似查询处理,但是只有企业版中才支持。
数据流程
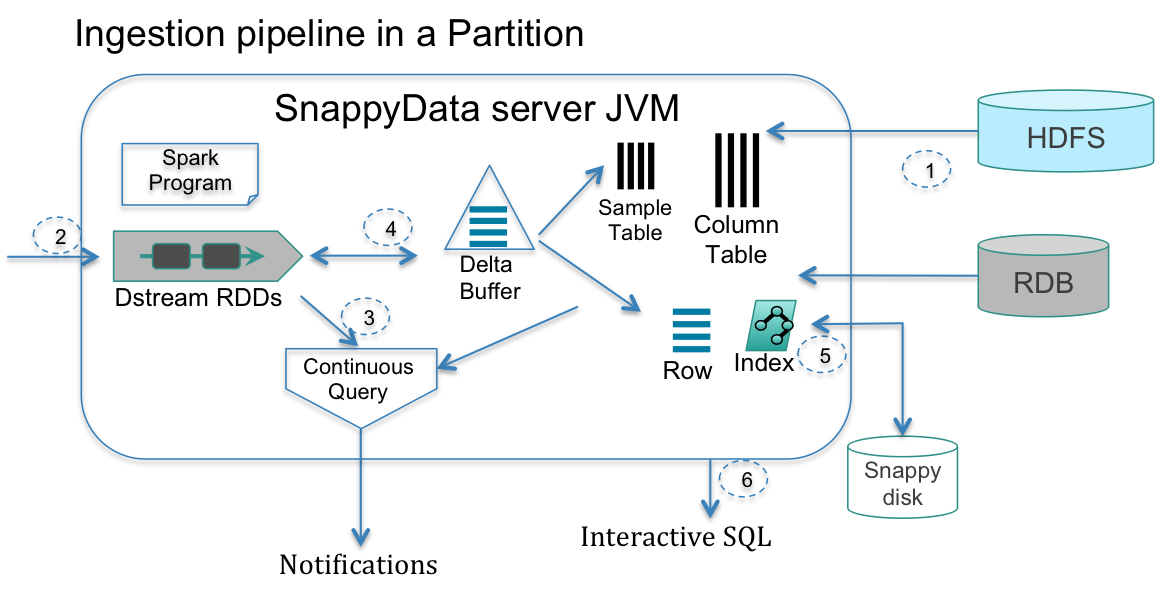
图中共有6个步骤,表明了数据从导入到查询的通常步骤:
1 | 1、原始数据导入:一旦集群建立,就可以从外部数据源(HDFS、Hive、MySQL、Oracle、csv等)中导入历史数据;行存或列存根据需求而定。 |
SnappyData角色
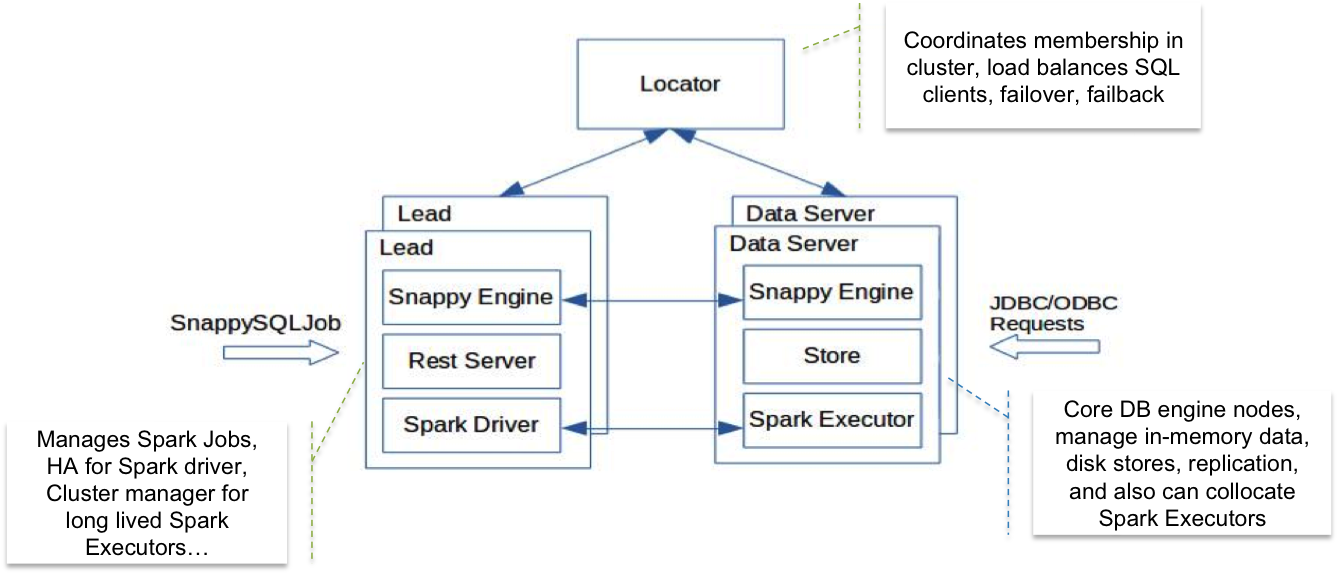
SnappyData集群是有3种不同的角色组成的P2P网络:
1 | 1、Locator:发现新成员的加入,接受客户端请求,失败恢复等。为了高可用,通常locator有2个,一主一备。 |
上图中我们可以看到,客户端通过JDBC或者ODBC,指定locator的地址进行连接;locator会将客户端的连接分发到不同的server;server负责解析SQL,并判断是否交给lead进行job部署,这里有些SQL语句是不需要由lead生成spark job的,例如show tables,行表上的操作,insert into XX values(xx)单点插入等;如果是复杂的SQL,则交给lead进行分发,具体的执行则分发到各个server执行计算。
混合集群管理器
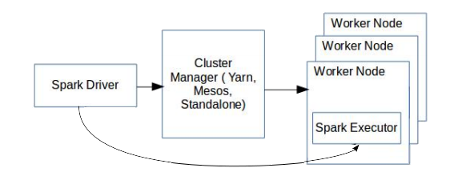
Spark主要是用于批处理操作,通常对大量数据的处理(包括多表join等)时间都比较高。但是这对于SnappyData来讲无法接受,好在SnappyData利用了全内存、与Spark存储格式一致、colocate数据本地化等特点,得以将延迟降低到秒级或者毫秒级。
除此之外,SnappyData还必须满足额外的需求才可以作为一个实时的SQL数据库使用,例如高并发、状态共享、高可用以及数据一致性。
高并发
面对高并发,SnappyData将客户端所有的请求分成2类:
1 | 1、低延迟的请求 |
对于低延迟的请求,SnappyData会跳过Spark的调度,而是直接由GemFireXD处理数据,例如上边提到的行表的操作,点插入,show或describe命令等;
而对于高延迟的请求,则会根据Spark的Fair调度机制分发到各个server执行计算,例如列表上的select或者点更新,批量DML等。
状态共享
SnappyData是一个Shared Nothing存储,完全的分布式本地存储。但是不同的job之间,数据是可以共享的。原因就是因为SnappyData本身也是个存储引擎,其数据完全驻留在内存中,因此天然具有状态共享的优点。
高可用
发现服务:SnappyData是个P2P网络,因此它提供了发现服务,即提供一个包括lead和server的列表。
组协调器:最先加入的成员自然成为了coordinator角色,这个角色会不断的检测当前的member,并与初始的列表进行对比以确保所有成员是可用的。当有新的成员加入时,根据发现服务,coordinator会将新加入的成员加入列表并把一些数据同步到其节点中。
失败检测:对于节点失败是很容易检测到的;而对于网络分裂或者脑裂情况,就会比较复杂一些。SnappyData通过UDP neighbor ping等机制进行多次检测,以确定疑似的失败是否是真正的失败。
HA:SnappyData另一个高可用的地方表现在其Lead节点的HA,即可配置primary角色和standby角色。选举则根据分布式锁服务,先到的就是primary。
数据一致性
SnappyData提供了read committed和repeatable read两种事务隔离级别。在写入发生时,会对所有的副本加排他锁,这里有个假设就是很少出现不能获得排他写锁的情况,提交的时候会应用到所有的副本。
总结
到此为止,关于SnappyData的架构,基本就讲完了。我们后续会继续根据SnappyData的使用写一些应用类的博客。
也欢迎大家加入SnappyData专业中文社区和SnappyData中国用户组微信群进行交流。
引用
SnappyData: Streaming,Transactions,and Interactive
Analytics in a Unified Engine