Snappy-SQL交互命令行
通过Apache Derby ij tool,SnappyData实现了一个交互式的命令行工具: snappy。通过此脚本便可在SnappyData集群中运行SQL命令或SQL脚本,此文件位于bin目录下。
在创建JDBC连接前,你可以通过snappy.history指定一个路径,来保留未来执行的所有SQL命令:
1 | $ export JAVA_ARGS="-Dsnappy.history=/temp/snappydata-history.sql" |
注意:这里选择snappy脚本和snappy-sql脚本都可以,snappy-sql最终也是要调用snappy脚本执行。
接下来就可以创建连接并执行SQL命令,需要注意的是所有命令都以分号结尾,并且不区分大小写。
通常我们指定一个locator hostname进行连接,默认端口1527.
1 | $ ./bin/snappy |
指定locator后,locator会将连接请求根据负载情况发送到某个server节点并返回客户端已经连接的消息,客户端执行的所有sql命令都由这个server进行解析。
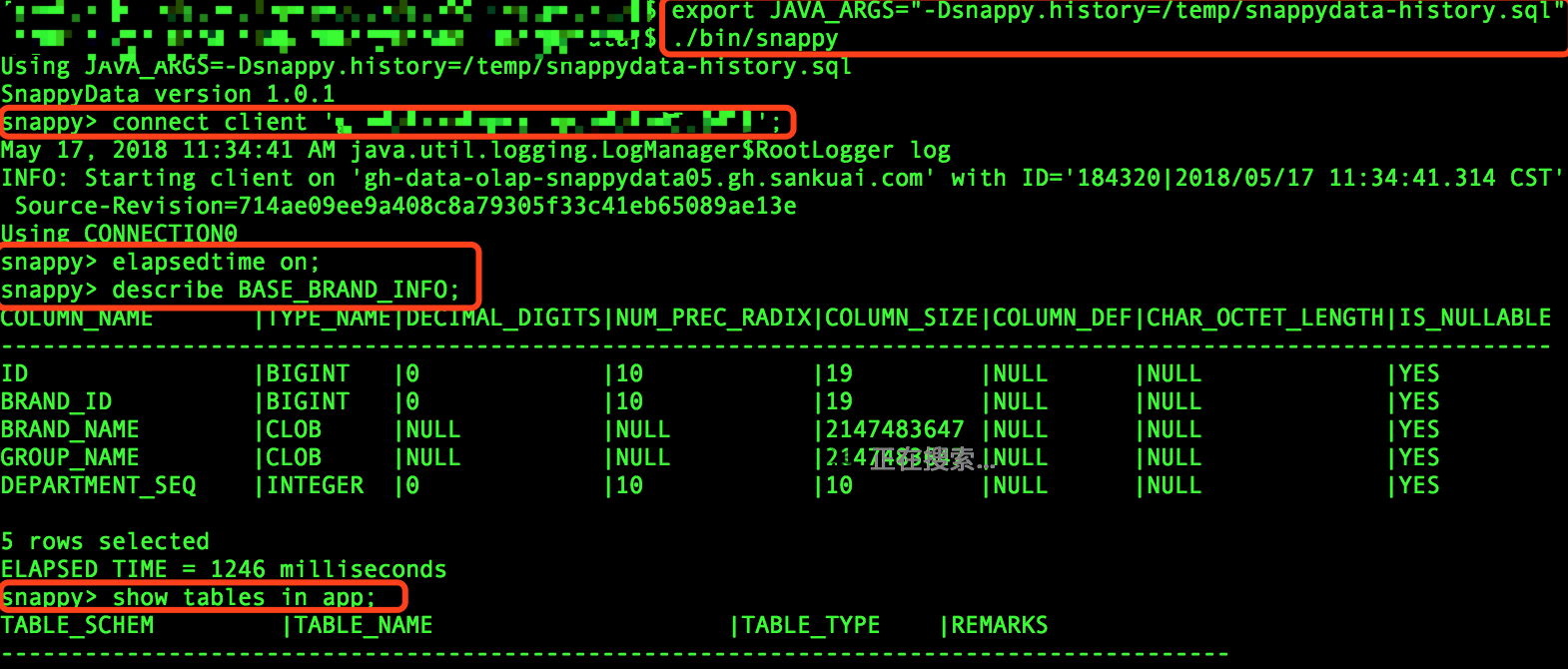
当然也可以执行show、describe等命令来查看其他信息,具体命令可通过help来查看帮助。
1 | elapsedtime on; |
JDBC连接
JDBC连接到SnappyData 1.0.0(1.0.1),需要引入如下依赖:
1 | <!-- https://mvnrepository.com/artifact/io.snappydata/snappydata-store-client --> |
Driver要选择io.snappydata.jdbc.ClientDriver,例如:
1 | Class.forName("io.snappydata.jdbc.ClientDriver"); |
第三方客户端工具
为了便于开发测试,用户也可以选择一个第三方工具进行JDBC连接。一般情况下所有工具都没有自带SnappyData的Driver,所以用户需要手动将所需的依赖拷贝到lib目录或者通过配置添加,并指定Driver class为io.snappydata.jdbc.ClientDriver。
这里我们以“SQuirrel SQL”的客户端工具为例,来说明配置的步骤。
需要的依赖
依赖列表如下:
1 | snappydata-store-client-1.6.0.jar |
其中1-7都封装在snappydata-store-client中,8则属于libthrift,9-10封装在spark-unsafe_2.11中。
界面配置
在Drivers界面,添加一个新的Driver,并将需要的依赖分别添加,Class Name项选择“io.snappydata.jdbc.ClientDriver”。
1 | Driver Name: Apache SnappyData |
截图如下:
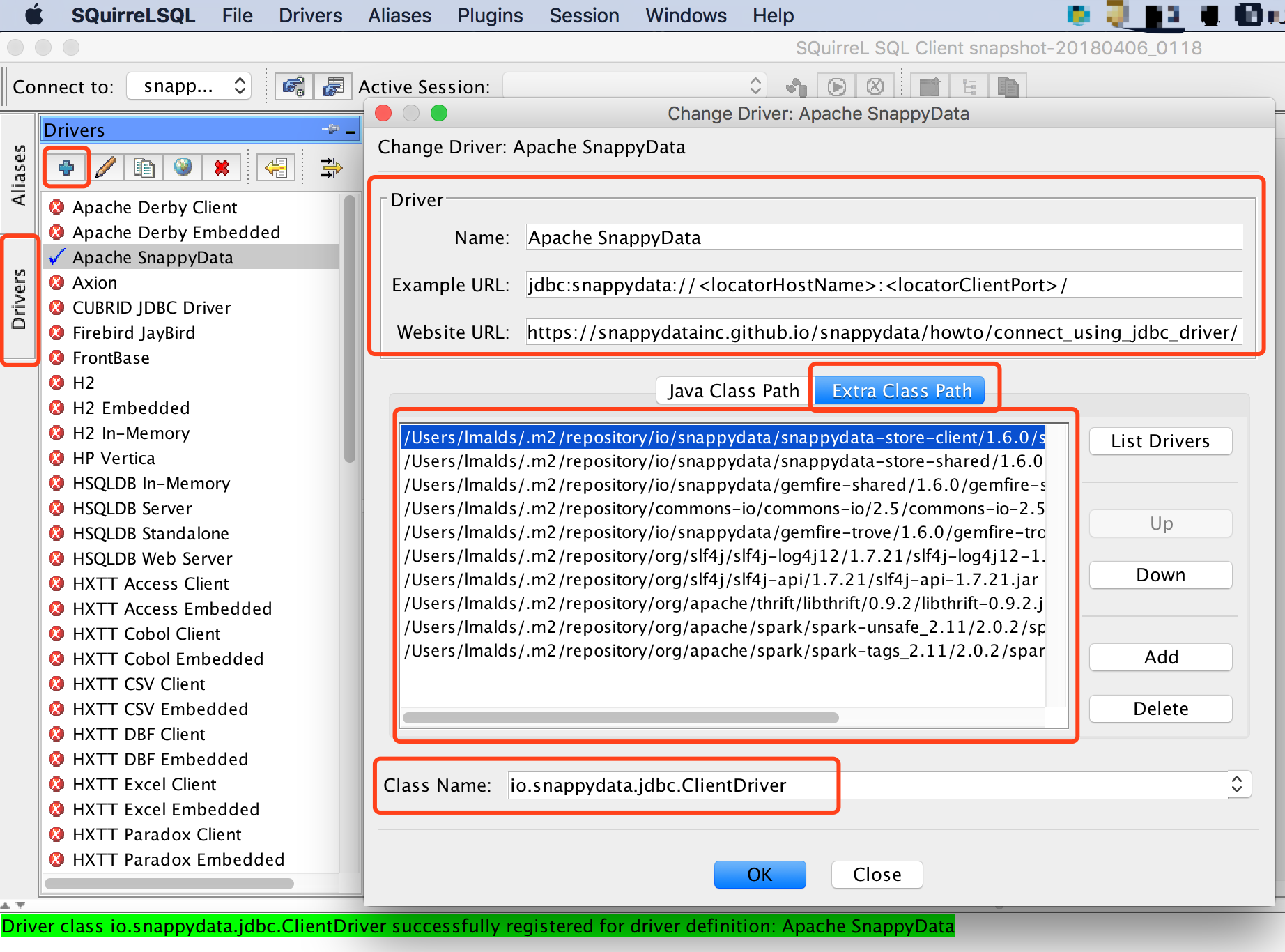
Driver配置完成后,开始配置URL连接,在Aliases界面,添加一个SnappyData Driver的URL连接。
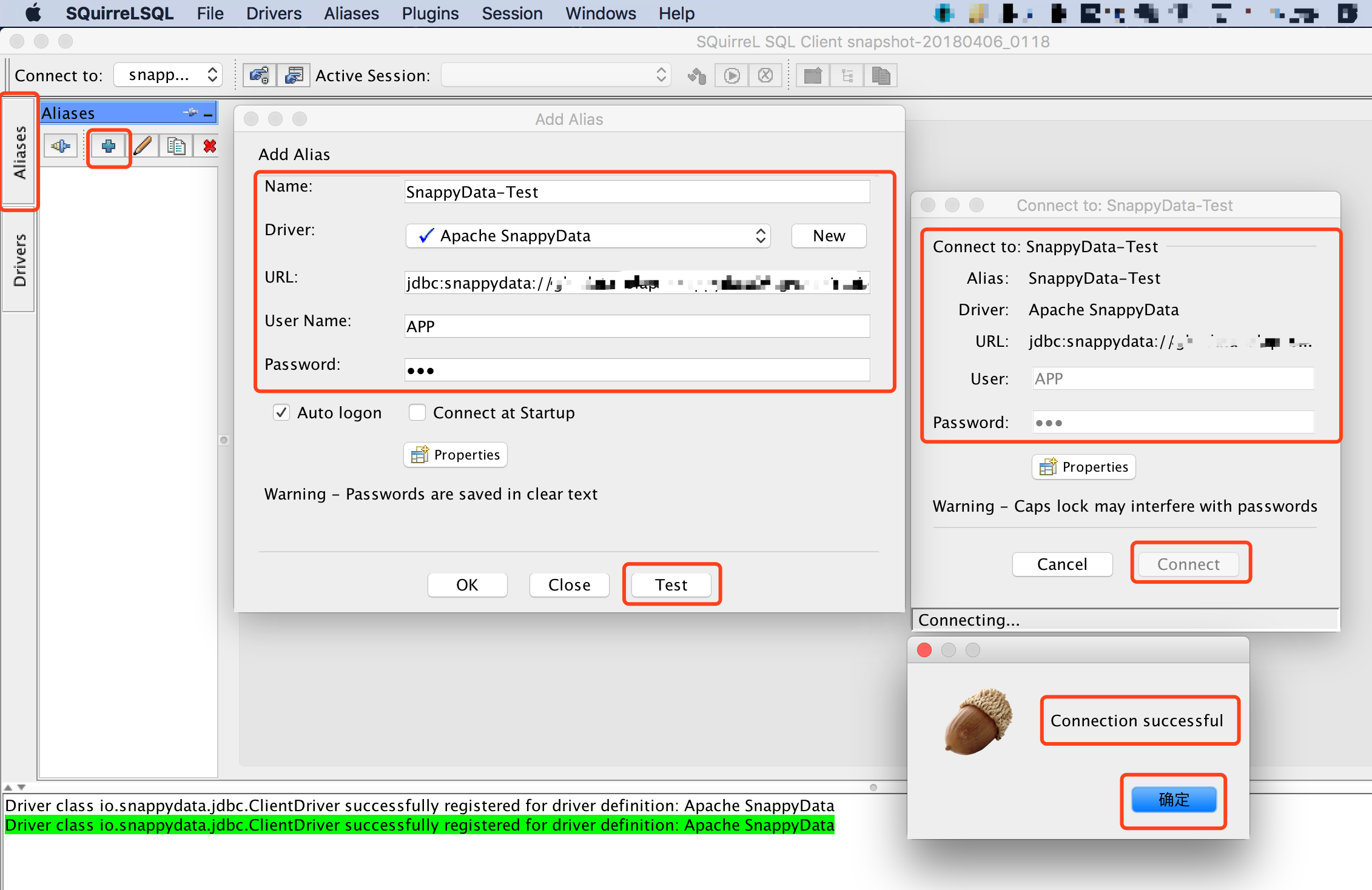
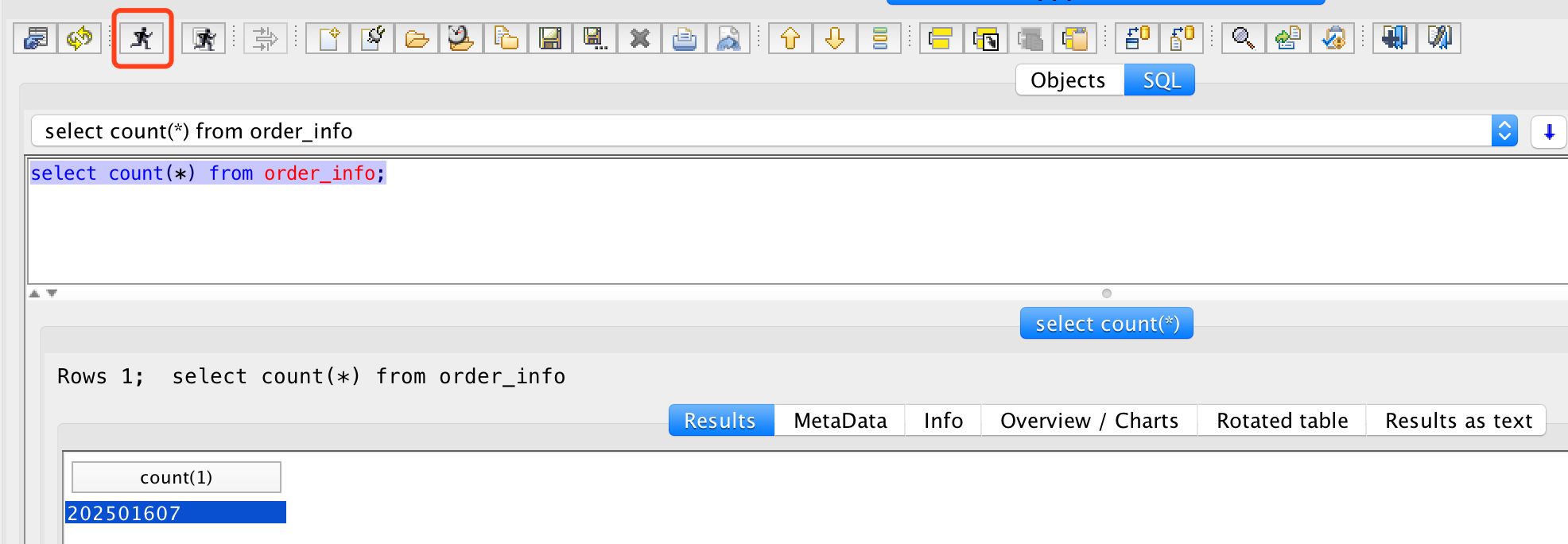
连接成功后,执行查询:
总结
从使用角度来说,SnappyData完全可以当作MySQL使用,SQL语法是标准SQL+Spark SQL,支持分析函数,比MySQL功能还要强大。
从性能角度看,SnappyData的OLAP功能和MySQL没有可比性,OLAP功能强大。
从灵活度角度看,SnappyData支持自由的探索,AdHoc查询用起来非常灵活、快速、实时,这点是Kylin和Druid等预聚合系统无法达到的。
从易用性角度看,支持SQL,这对于分析人员来讲门槛降低,效率大大提升。
从业务角度看,支持update、delete、支持join,业务分析更灵活。
引用
Snappy-SQL Shell Interactive Commands