update点更新
Spark中的RDD具有不可变性,但是SnappyData中数据是可变的,即使是列表(column table),也是支持更新的。
对于实时的OLAP来讲,这是非常重要的功能,比如订单的状态、剩余的库存等,都是需要实时update操作的。
有些业务也许是纯update只保留最新记录,而有些业务update旧数据的状态,也要insert新数据,以便分析历史变化趋势。
这种复杂的业务数据如果放到druid中,让分析变得非常困难。而SnappyData支持各种类型的update和insert操作,让分析复杂的业务数据变得更简单。
SnappyData中标准update语法如下:
1 | UPDATE TRADE.CUSTOMERS SET ADDR=NULL, SINCE=NULL WHERE CID > 10; |
我们实际生产中,在开始阶段是按照这种点更新操作的,但是由于并发很多,数量庞大,导致lead的压力较大,所以将部分业务逐渐的由点更新变为了批量更新。即降低部分数据的实时性(10秒级),换取更大的吞吐量(数万级)。
update join – 批量更新
SnappyData也支持批量更新,总体来说有2种形式,第一种是更新为固定的值,第二种是更新为另一个表中的值。
批量更新为固定的值
SnappyData中2个列表join,你可以将一个表中某些列的值,批量更新为固定的值,SQL如下:
1 | UPDATE a |
在实际生产中,我们找了其中某个批量update语句,数量分别为9.2亿条和4.5万条记录的2个列表的join,匹配量3.6万,其执行时间为0.6秒,执行计划如下:
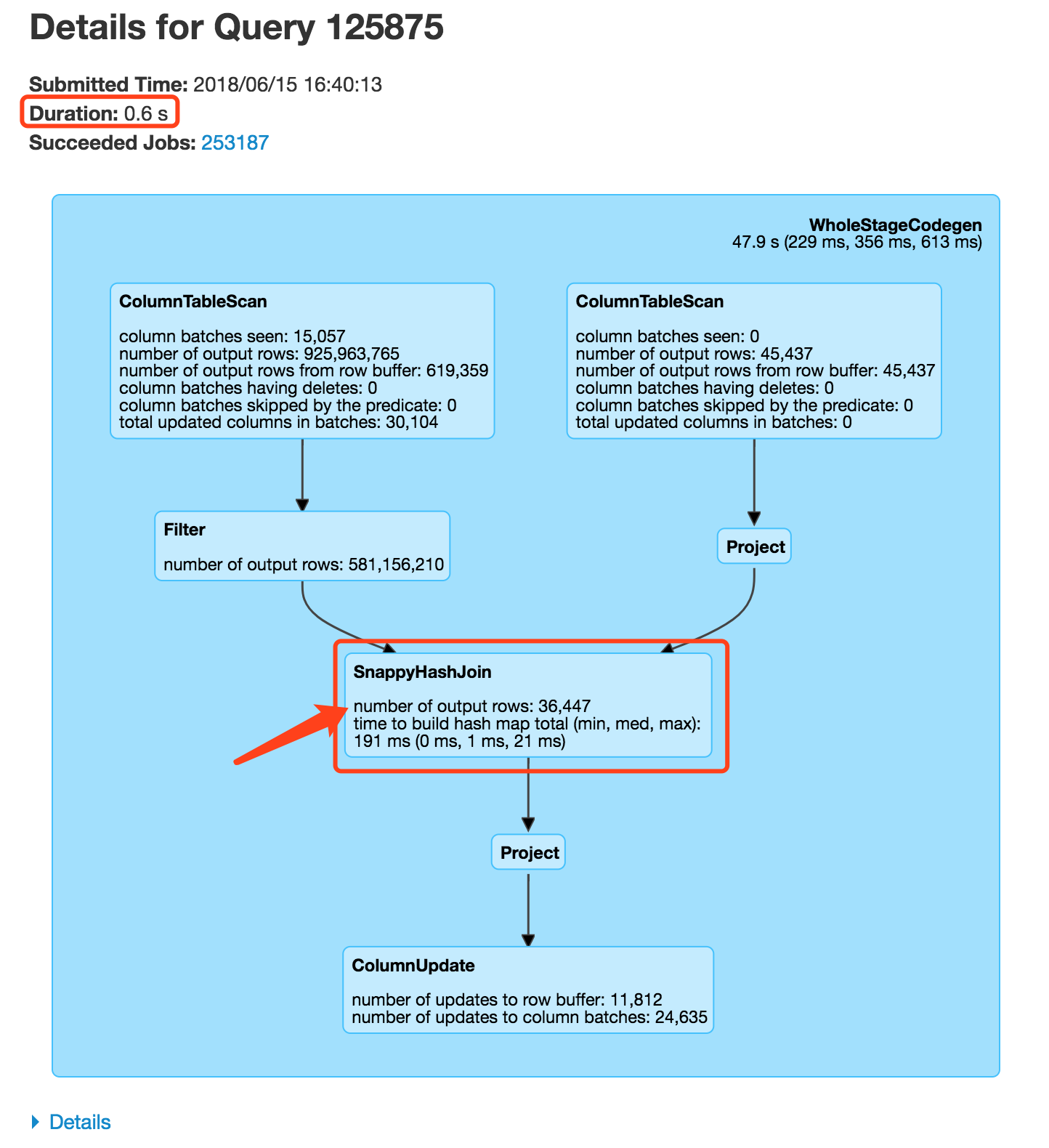
批量更新为另一个表中的值
第二种是更新为另一个表中的值,SnappyData中提供了update join的功能,标准SQL如下:
1 | UPDATE TRADE.SELLORDERS |
我们在生产中也有这类的需求,1个7亿条和300万的列表join,耗时0.2秒,执行计划如下:
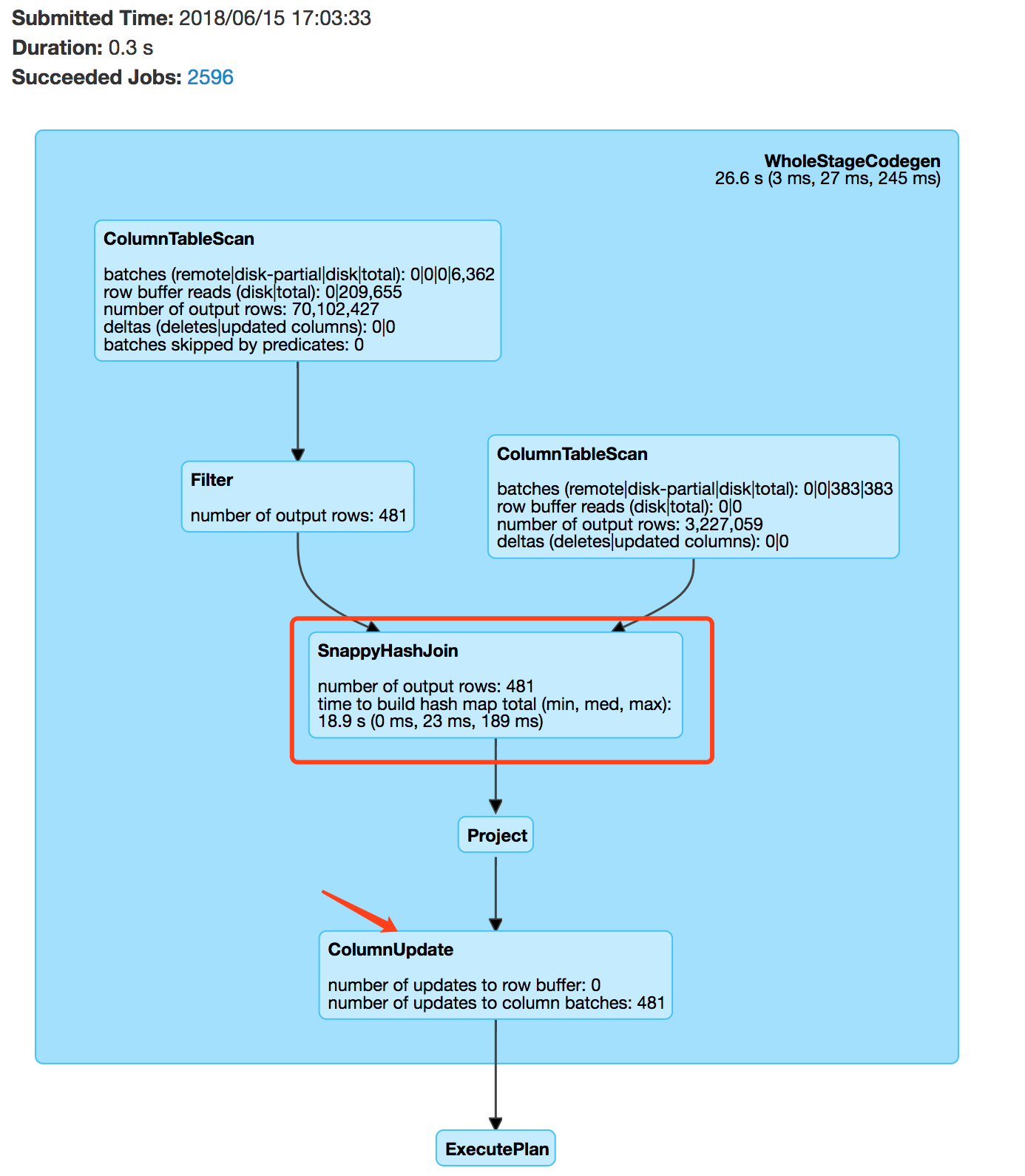
可以看到,在本地join的情况下,速度在毫秒级内完成。
put into – replace操作
SnappyData中还有一种功能,类似于merge、upsert或MySQL中的replace into功能。即2个表join,如果join key存在,则进行update(delete && insert),否则insert。
我们只以column table为例说明。列表如果需要put into的功能,则在DDL时必须明确指定KEY_COLUMNS属性(可以是组合列),即唯一标识一行数据,否则执行时报错。
DDL中指定KEY_COLUMNS的例子如下:
1 | create table XX( |
put into的标准SQL如下:
1 | PUT INTO NEWEMPLOYEES |
我们实际也用到了put into语法,执行计划如下:
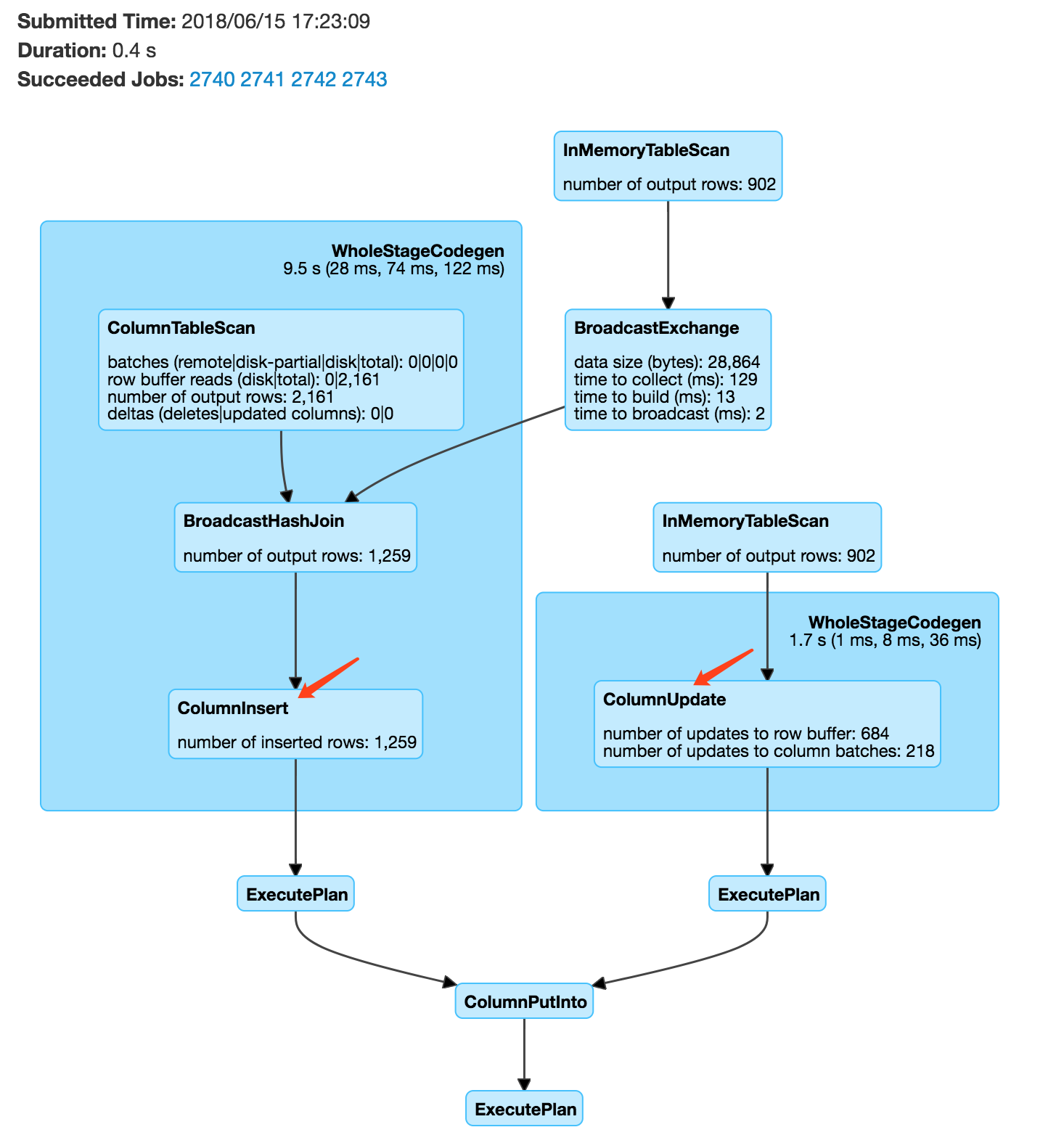
总结
SnappyData支持历史数据的更新,这个功能极大的提高了分析的灵活性和实时性。
同时支持了点更新以及各种批量的更新和替换,使得用户可以在低延迟和高吞吐之间做个平衡,按需实现。