OLAP简介
On-Line Analytical Processing,简称OLAP,即联机分析处理,其主要的功能在于方便大规模数据分析及统计计算,对决策提供参考和支持。
OLAP发展到现在的阶段,很多的查询分析需求具有以下4种显著的特点:
1 | 1、数据量大 |

根据存储类型,OLAP又分为ROLAP(RelationalOLAP)、MOLAP(MultidimensionalOLAP)以及HOLAP(HybridOLAP)。
根据处理类型,OLAP又分为MPP架构、搜索引擎架构和预处理架构。
在开源领域OLAP的解决方案中,包括了诸如Presto、SparkSQL、Impala以及SnappyData等MPP架构和ROLAP的引擎;也包括了Druid和Kylin等预处理架构和MOLAP的引擎;同时还包含了ES这种搜索引擎;除此之外,还有ClickHouse以及IndexR这种列式数据库用于OLAP分析。
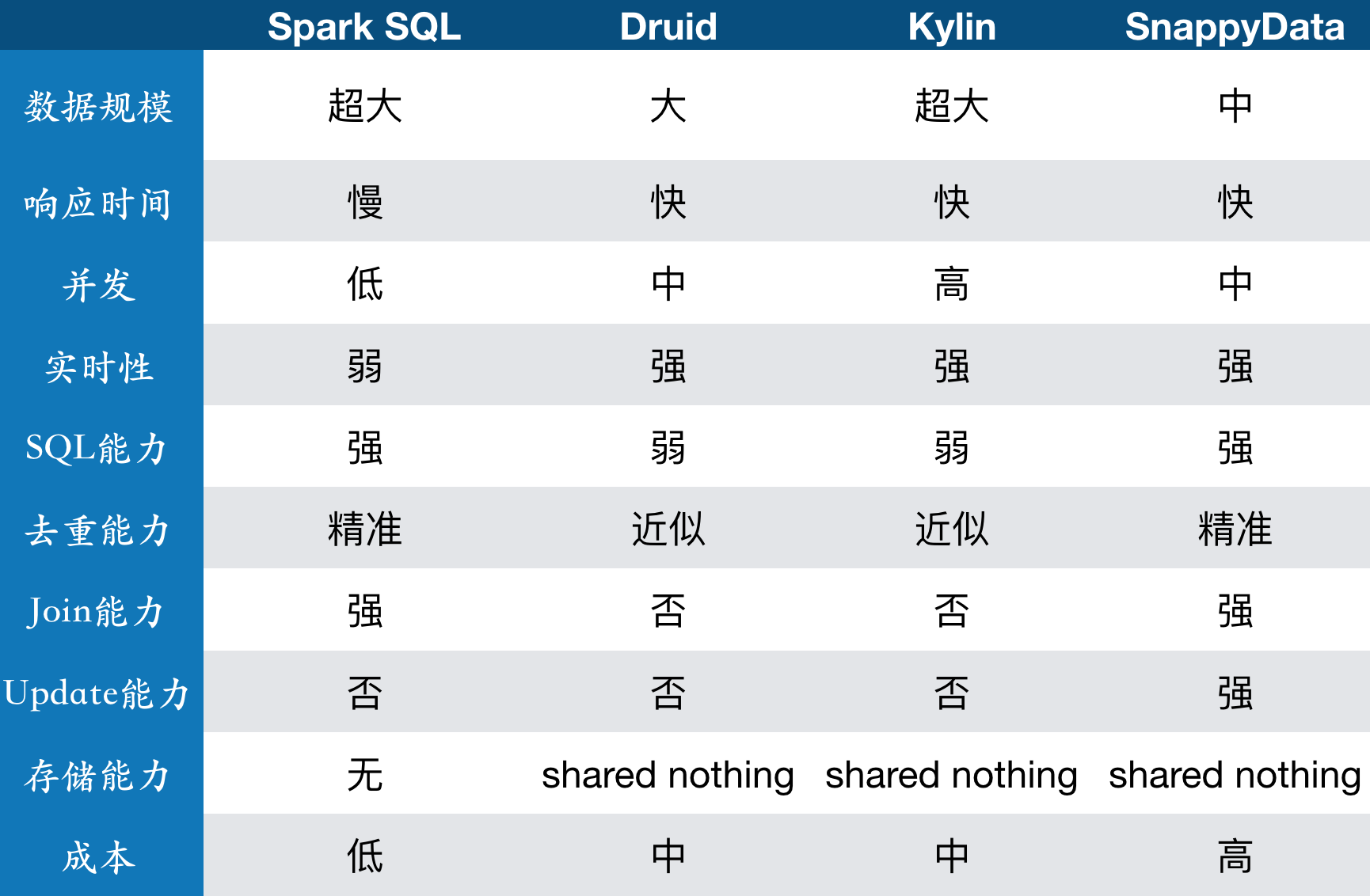
下面我们就这些开源引擎,从上述中以下几个方面进行对比:数据规模、查询性能、灵活性、易用性、处理方式以及实时性进行对比。
分布式开源OLAP引擎
基于MPP架构的ROLAP引擎
Presto、Impala以及Spark SQL,都是利用关系模型来处理OLAP查询,通过并发来提高查询性能。
这类引擎的优点和缺点如下:
1 | 优点: |
我们以Spark SQL为例来说明,由于其本身只是个计算引擎,而非存储引擎,导致其需要从外部加载数据,使得数据的实时性得不到保证;同时当涉及多表join时,其查询性能很难得到秒级的响应。
因此,其实时性和查询性能较弱,所以只适合那些对实时性要求不是很高,但灵活性很强的需要多表join的ad-hoc类查询以及需求变化较频繁的查询。
目前开源社区出现了一种依托Spark SQL,同时自己存储数据的一类OLAP引擎,比如TiSpark以及SnappyData。
关于TiSpark项目,其虽然以TiKV为存储减少了数据加载的延迟,使得实时性可以得到保证,但是其在数据量较大时的join,查询响应依然得不到保证;同时对于窗口函数的分析不支持,部分adhoc需求也得不到有效保证。
关于SnappyData,其也是个存储引擎,而且表join时通过数据存储本地化以及其他优化,有效将性能差、实时性差的缺点避免掉,我们会在最后就SnappyData做个总结。
预计算引擎与MOLAP
Kylin是完全的预计算引擎,通过枚举所有维度的组合,建立各种Cube进行提前聚合,以HBase为基础的OLAP引擎。
Druid则是轻量级的提前聚合(roll-up),同时根据倒排索引以及bitmap提高查询效率的时间序列数据和存储引擎。
Kylin的优缺点如下:
1 | 优点: |
Druid的优缺点如下:
1 | 优点: |
因此,Kylin适合对实时数据需求不高,但响应时间较高的查询,且维度较多,需求较为固定的特定查询;而不适合实时性要求高的adhoc类查询。
Druid适合那种数据量大,对实时性要求高且响应时间短,以及维度较少且需求固定的简单聚合类查询(sum,count,TopN),多以storm和flink组合进行预处理;而不适合需要join、update和支持SQL和窗口函数等复杂的adhoc查询。
如果分析人员想用SQL进行复杂的分析操作,那么Druid不适合。
搜索引擎架构
ES是典型的搜索引擎类的架构系统,在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型提高查询性能。对于搜索类的查询效果较好,但当数据量较大时,对于Scan类和聚合类为主的查询性能较低。
ES的优缺点如下:
1 | 优点: |
因此,ES适合那种全文检索,且数据规模较少时过滤条件很多的聚合查询,并发度也不大的场景。
同样,如果分析人员想用SQL分析,那么也不适合ES。
纯列存OLAP
ClickHouse是个列存数据库,保存原始明细数据,通过MergeTree使得数据存储本地化来提高性能,是个单机版超高性能的数据库。
ClickHouse的优缺点如下:
1 | 优点: |
因此,ClickHouse适合数据规模不大情况下的单机且单表的数据分析。实际场景有待检验。
SnappyData
SnappyData是个计算与存储引擎,全内存、行列混合存储且完全不需预处理,支持SQL与Spark SQL,兼顾MPP的特点且colocate特性使得数据本地化,支持join、列表的update以及窗口函数等任意的adhoc查询。
SnappyData的优缺点如下:
1 | 优点: |
因此,SnappyData适合那种数据规模中等(PB以下),需求变化加多,实时性要求较高、响应时间较短且复杂的窗口函数类查询;同时适合查询明细数据以及探索式的adhoc查询。
如果数据规模不大,且希望找到一种简单易用且实时性要求高的多维OLAP引擎,最重要的是可供分析人员使用的SQL的引擎,那么SnappyData比较适合。前提是需要在成本与效率之间做个平衡,SQL固然能提高开发效率,但内存较大的服务器成本也确实相对较高。
引擎对比