Shasta系统架构
Google内部广告业务的数据分析,需要满足3方面的需求:
1 | 1、查询的延迟要低 |
为了支持这3方面的需求,Google内部开发了一个叫做Shasta的广告分析引擎,允许用户以较低的延迟、简单的类SQL语句查询复杂的、实时更新的数据。
具体的需求如下:
1 | 1、数据存储多样化(F1、Mesa,Shasta本身并不是存储引擎) |
这个类似于实时数仓的Shasta,并没有采用任何预计算或是物化视图,虽然物化视图和预计算可以一定程度的降低查询延迟,但是其数据更新有周期性的延迟、写入时的开销较大以及需求变化大,再加上业务的表非常多,所以导致预计算和物化视图不太现实。
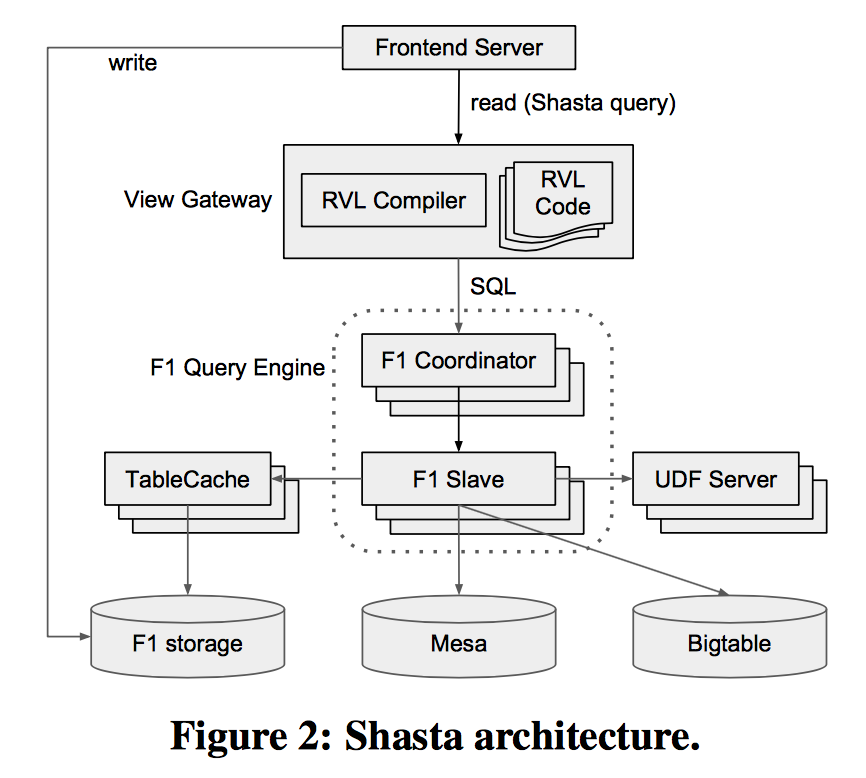
Shasta能做到上面提到的3点需求,主要依赖于3个组件:
1 | 1、TableCache |
其中RVL(Ralational View Language)语言使得查询表达简单且做了隐士聚合,提高了效率;TableCache在SQL引擎和F1数据库之间做了快照的缓存,且查询时可以通过时间戳和Root ID提高效率;UDF Server独立部署且代码重用,同样提高了效率。
RVL
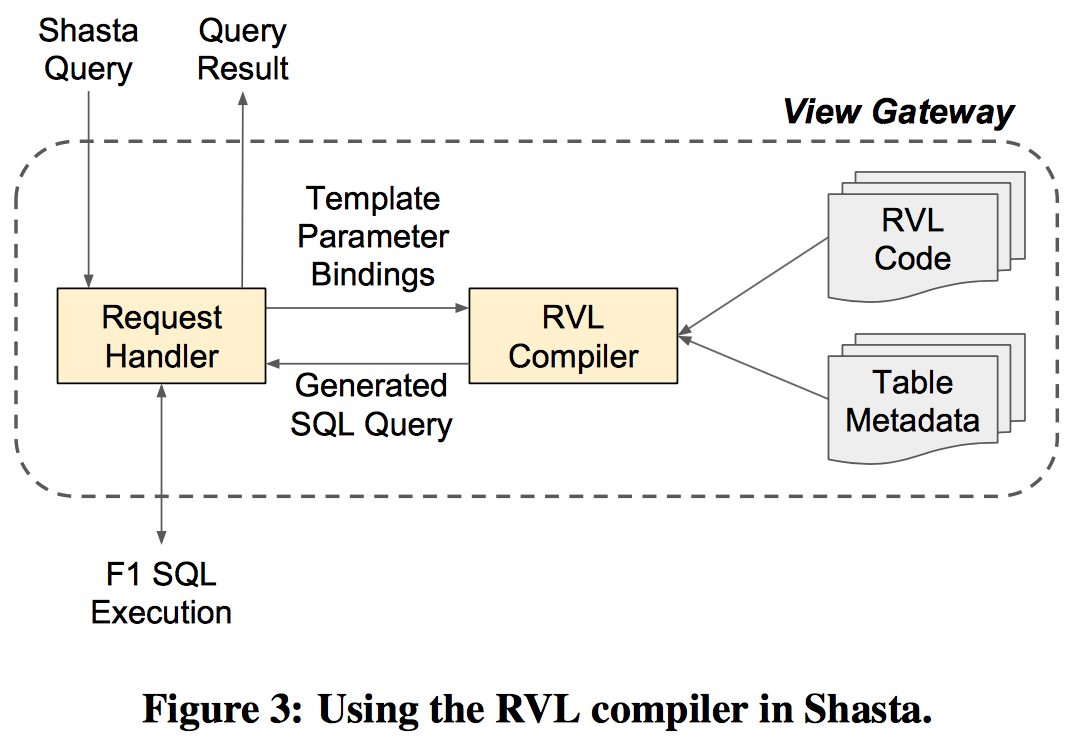
RVL是个查询语言,跟SQL类似,最终也会被编译解析成SQL语句。
之所以设计这个RVL层,从论文中看主要因为太多的表连接使得写出来的SQL太过复杂;而且表达这种复杂SQL时,对广告业务或销售人员来讲太难了,毕竟需要了解50多张甚至更多的表结构,成本太高;同时,RVL的设计可以对业务进行高层的抽象,即2个表可以join为一个视图模版,同时其他的业务也可以用到这个视图,即代码复用,这个设计也是以使用简单为目的。
RVL的视图定义还支持参数绑定,因为毕竟它只是个视图定义,所以视图参数化使得查询时逻辑更清晰。
RVL还有个特点是隐士聚合,即当投影某个measure列时,可以定义好聚合类型,这样分析人员表达复杂的聚合操作时更加容易。
此外,RVL还做了诸如列剪枝、过滤下推、左连接剪枝等优化。
总体感觉,RVL的设计初衷是为了简化表达,逻辑清晰,提高效率。毕竟RVL终究还是要解析成SQL去执行的。
F1查询引擎
F1是Google内部的分布式MySQL,当SQL提交到F1的Coordinator时,它将请求分为中心化的请求和分布式的请求,即简单的请求直接在F1对应的Server上执行,而复杂的请求则将SQL转换为DAG模型在F1的slave中并行执行。
F1的查询引擎有下面3个特点:
1 | 1、hash分区 |
分布式的join消耗很大,采用hash分区可以将计算和数据都在本地进行,这样可以极大的提高join时的效率。
视图的定义是对业务的高层抽象,因此父视图的执行计划以及数据就可以进行缓存,类似于Oracle中的With语句,即先定义一个子集合,下面的查询如果需要反复使用上边定义的子集合时,表达会很清晰且有数据缓存的优化空间。
Shasta本身是个计算引擎,存储的数据位于F1、TableCache或者Mesta和Spanner中,因此设计了取数据的插件,加速数据的加载。
TableCache
TableCache是F1引擎和F1存储之间的中间件缓存层。通过对TableCache指定元组(table,RootId,timestamp)来加速查询。
其中,(table,RootId)将F1中的数据行分成了很多的分片;其次数据是懒加载且cache也是分片的;最后timestamp提供多版本的数据,同时根据F1 change history日志进行更新。
事实上,Shasta的低延迟,主要原因还是在于TableCache的应用,通过将数据以多版本的快照形式存在分布式的缓存中以及数据与计算的本地化,实现了对数据的快速访问。
UDF服务器
UDF在SQL中很普通,但是F1中却是独立部署的,这样的好处不但可以复用代码,还可以减少F1引擎的GC压力,同时可以设置不同的并行度。
总结
我们从Shasta的论文可以看到,实时数据仓库的实现,如果采用预计算的方式,那么灵活性就不能满足;通过分布式的Cache以及join数据的本地化,使得后计算也成为可能。
SnappyData的实现思路与Shasta还是有相似之处,内存+本地化存储明细数据,使得完全的后计算既可以支持灵活多变的SQL需求,也可以通过SQL提高效率,还可以通过进一步的优化实现复杂分析下的低延迟的需求。