一、建表原则
SnappyData中的表可以简单分为维度表与事实表两类,除此之外还有流表、采样表与临时表等,这里只讨论维度表与事实表,用于实时的、自由的、极速的、探索性的OLAP分析(Realtime-OLAP)。
通常建议将数据量较少的(万级别以下)维度表设置为replicated的行表,这样维度表会在每个节点中分别存一份。但是如果遇到维度表比较大且也会发生变化时(十万、百万级别以上),建议将表创建为列表,hash分区键指定为与事实表相同的列,例如goods_id列,此时的维度表就变为了事实表。
事实表的数据量通常较大,一般设置为列表,hash分区键指定为与维度表相同的列,且明确指出与维度表进行colocate存储。目前列表上暂不支持对分区键的二级list分区或range分区。
二、建表DDL语句
1、维度表转事实表goods表
由于维度表数据量接近300万,且字段较多,因此占用的内存空间较大,并不适合设计成每个节点都存储一份的维度表,所以将原维度表设计为一张事实表,按照goods_id进行hash分区:

2、事实表order表
事实表的数据量较大,这里以订单表为例,同样按照goods_id进行hash分区,但要指定和goods表进行colocate存储:

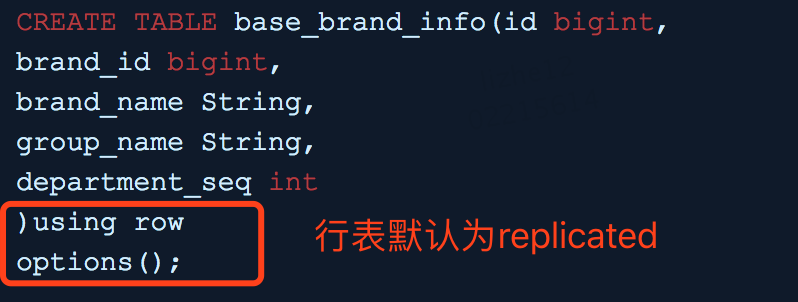
3、维度表brand表
可以将只有几千条的brand表设计为replicated的行表,这样brand表就会在每个节点都存储一份:
三、数据实时导入
SnappyData支持流表,允许接入kafka进行实时导入。但是对kafka的版本有要求。
我们的业务需要对表中的数据进行update更新操作,因此通过flink进行实时ETL或窗口类处理后,导入到SnappyData的维度表与事实表。
当进行纯粹的insert操作时,延迟在毫秒级;当需要进行update操作时,由于数据量较大,为避免lead的压力过大、避免server处理频繁的update操作,因此在flink中实现SQL的批量更新,延迟在1分钟,但更新效率极高,这也是在低延迟和高吞吐之间进行了一次取舍。
四、查询类型
可以将查询分为3类:单表查询;维度表与事实表join;事实表与事实表join。
1、单表查询
进行单表查询时,可以对表中任何一个字段进行任何类型的SQL操作,例如投影、选择、链接等,即可以对数据进行自由、极速的探索性ad-hoc类查询。
我们以订单表为例,查看过去7天的订单状态分布情况:
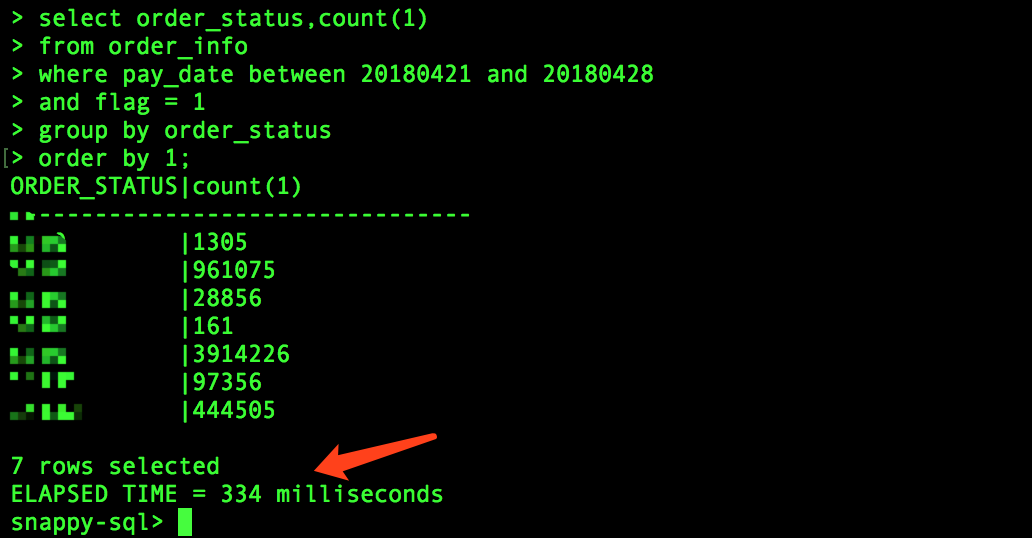
可以看到,在一个上亿记录的表上进行任意字段的聚合操作,延迟在毫秒级。
2、事实表与维度表join查询(流批join)
我们将goods表和brand表进行join,goods表是随着时间实时变化的,因此可以看作事实表,而brand基本不变,且是replicated的行表,因此看作维度表:
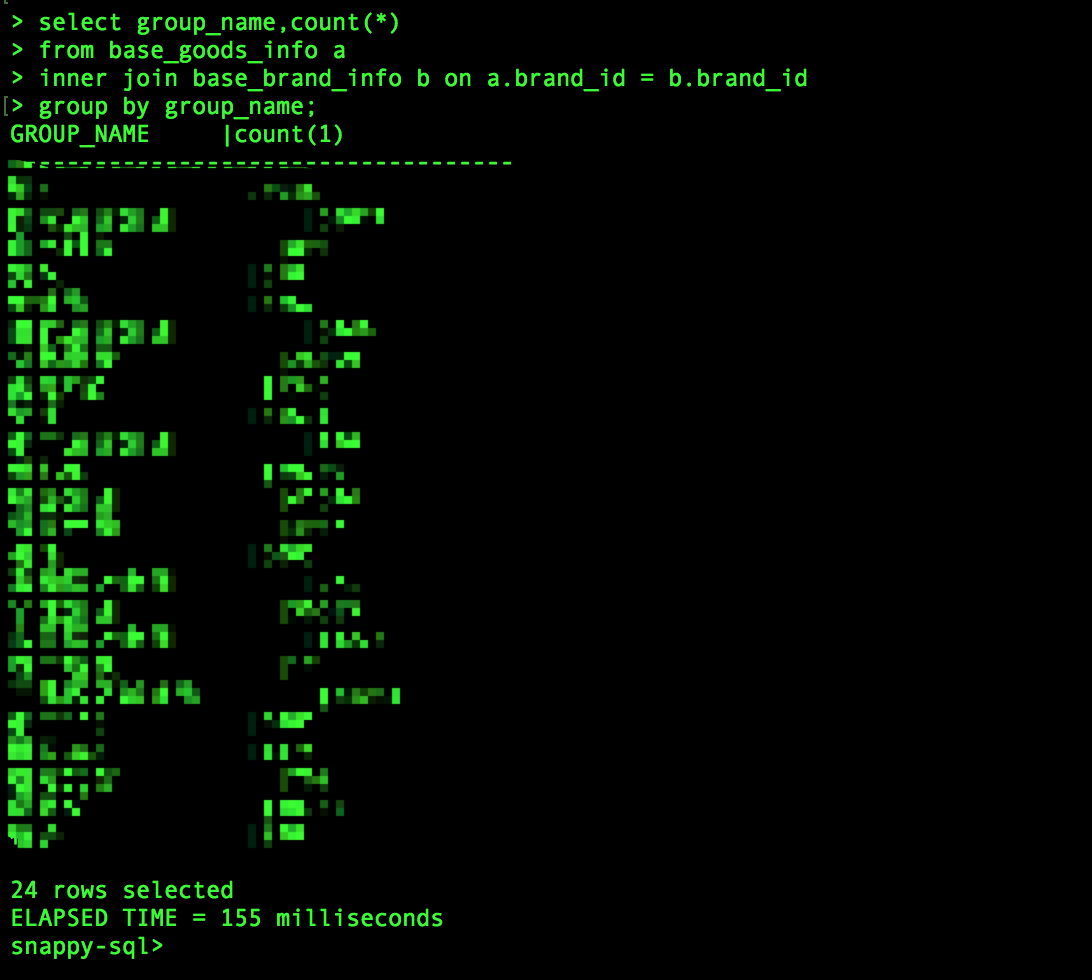
可以看到,查询在毫秒级完成。
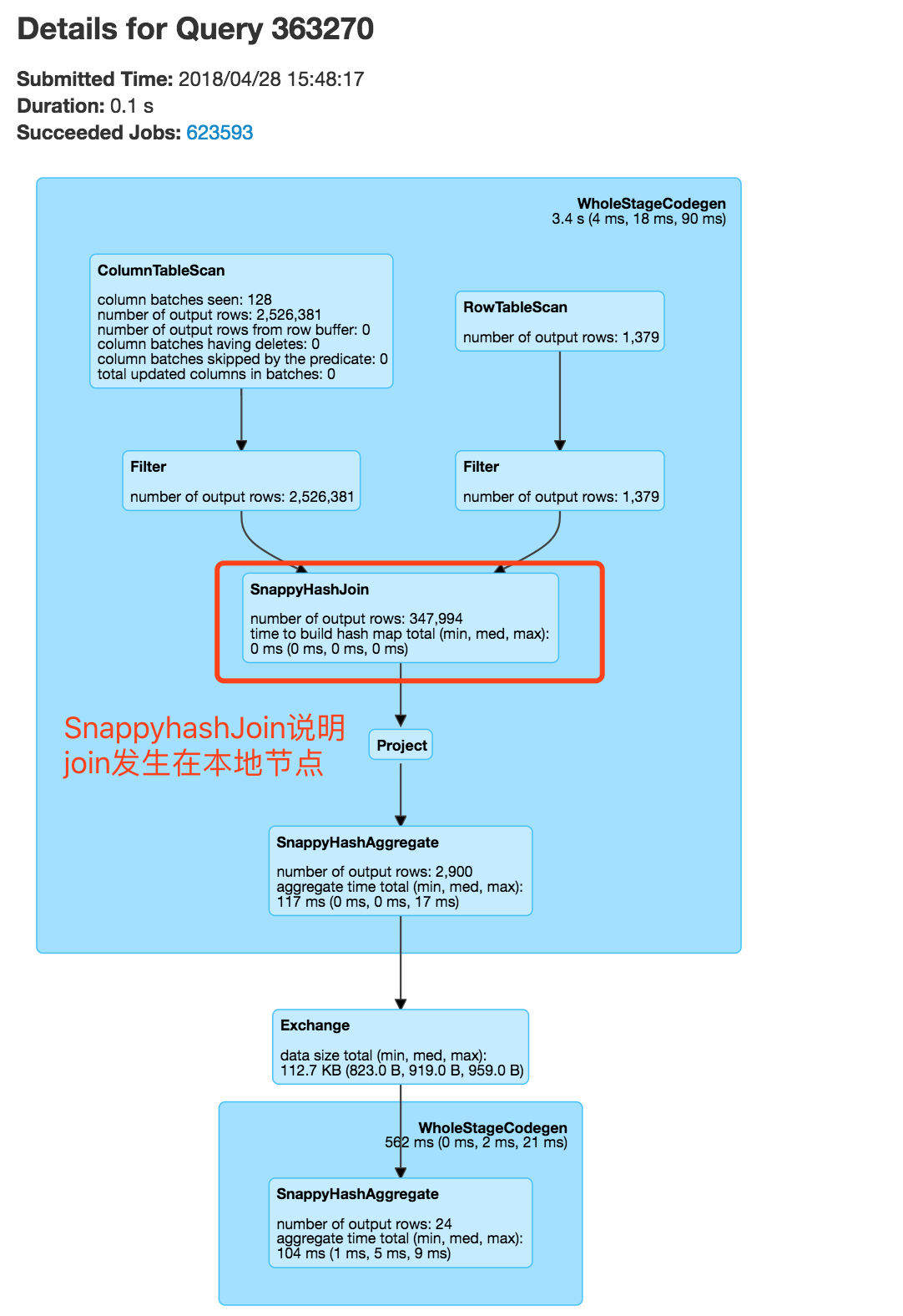
再看其执行计划,可以看到SnappyHashJoin,即两个表的join时,先在节点本地进行join,这样的效率比跨节点广播效率高的多。
3、事实表与事实表join查询(双流join)
这里我们举3个例子,其中既包含了涉及子查询,也包含了双流join与维度表join,也包括了自定义UDF。
先看下整体的查询耗时情况:
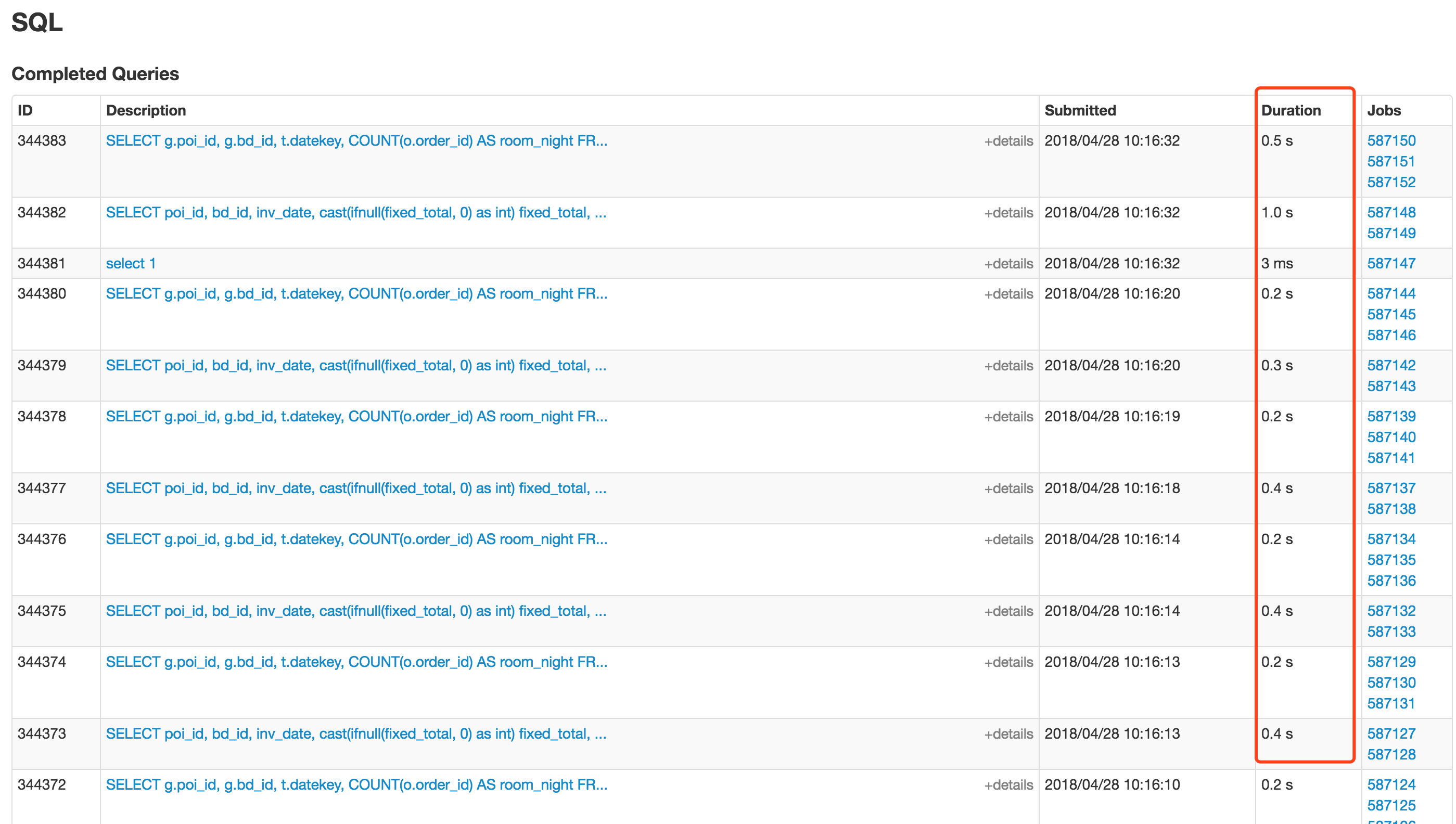
生产上的查询基本不到1s中就可以查询到,数据量从几亿到几十亿的join。
再看下具体的SQL执行情况。
3.1、双流join+维度表join
我们先看下2个事实表与1个维度表的join情况:
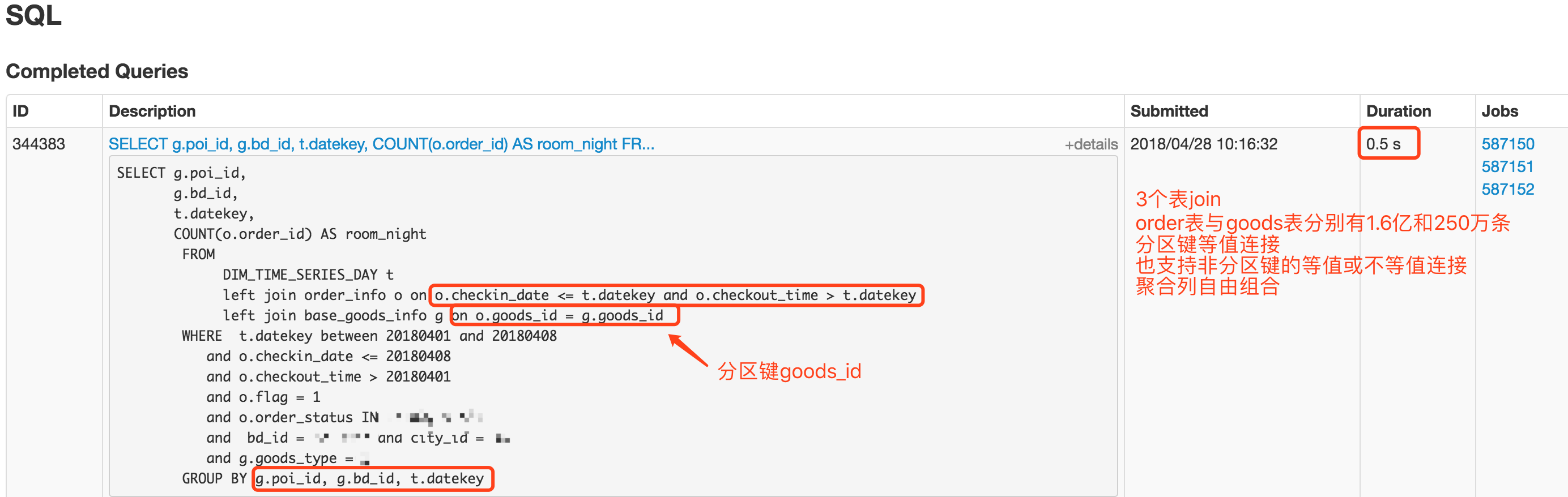
耗时在1秒内,数据量为1.5亿,聚合字段为非分区键。
3.2、子查询多表join
另一个例子是涉及到了子查询,且SQL中包含了各种内置函数以及窗口函数:
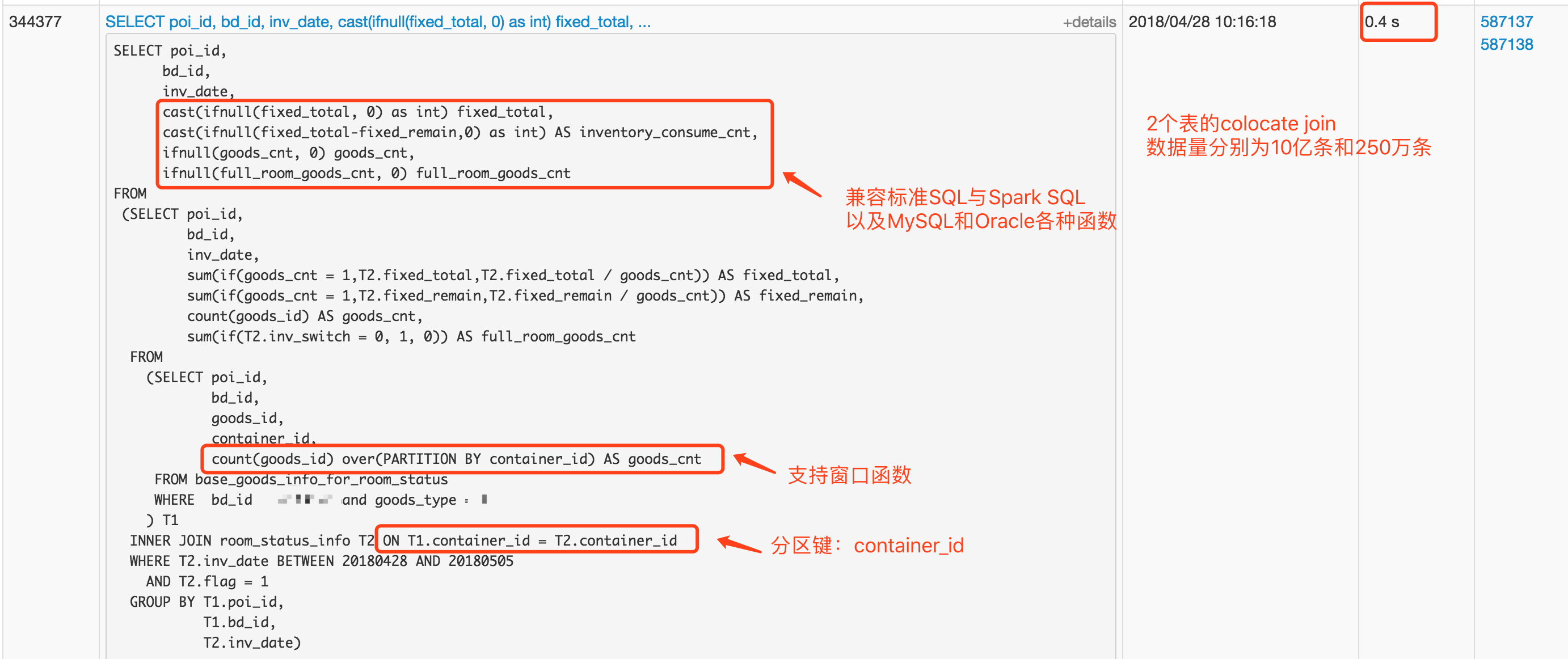
在10亿条数据的表上进行复杂的SQL查询,耗时0.4s。
其部分查询计划如下:
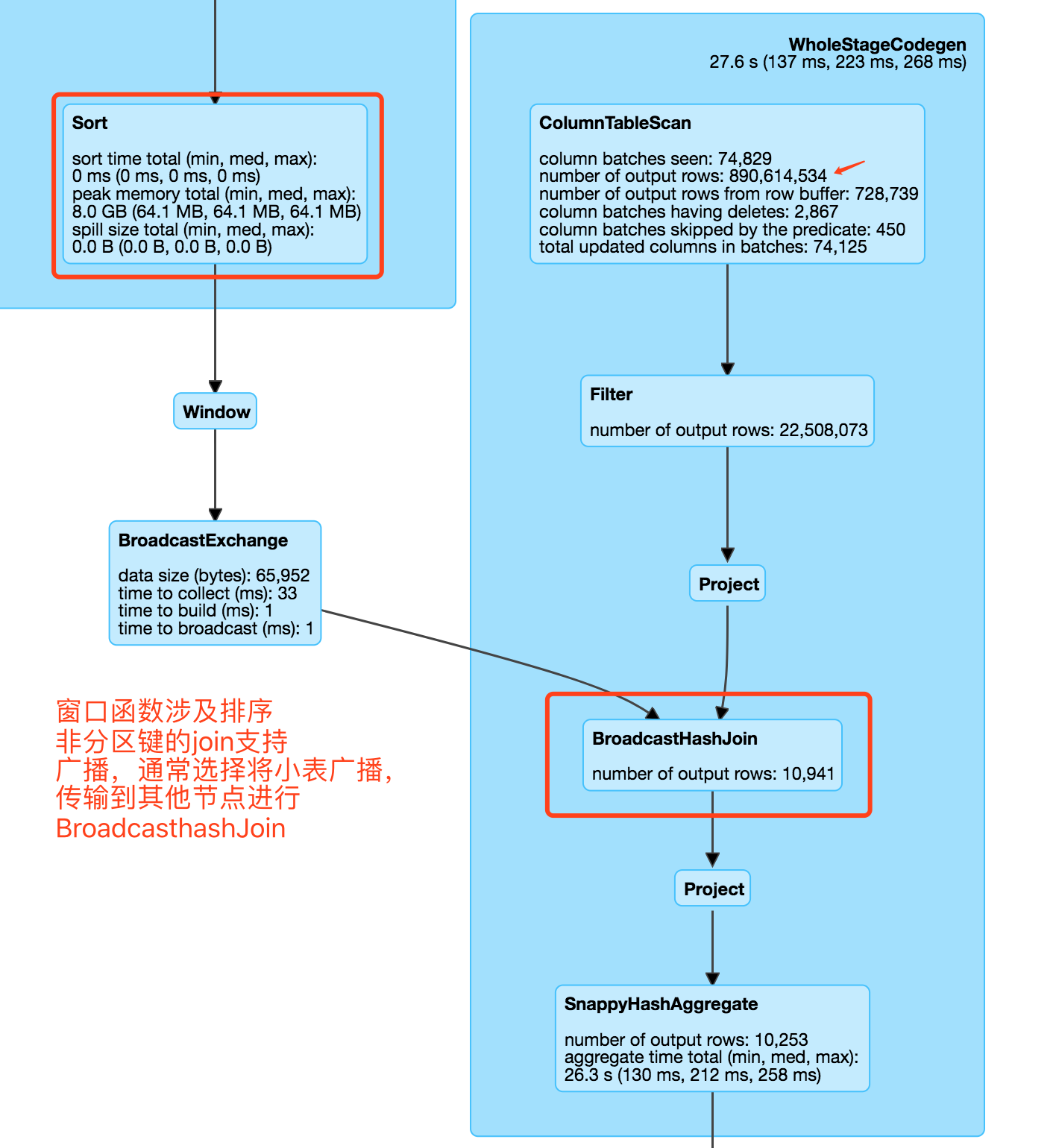
由于存在子集合,因此子集合数据会广播出去,效率没有本地join高。但由于广播的数据较小,因此查询效率并未受到太多影响。在设计查询SQL时,应尽量避免子集合,实在没办法避免时,应选择将较小的表作为子集合广播。
3.3、UDF后的join
由于涉及到排序以及复杂的运算,因此为了更高效的执行SQL,因此实现了自定义UDF函数。
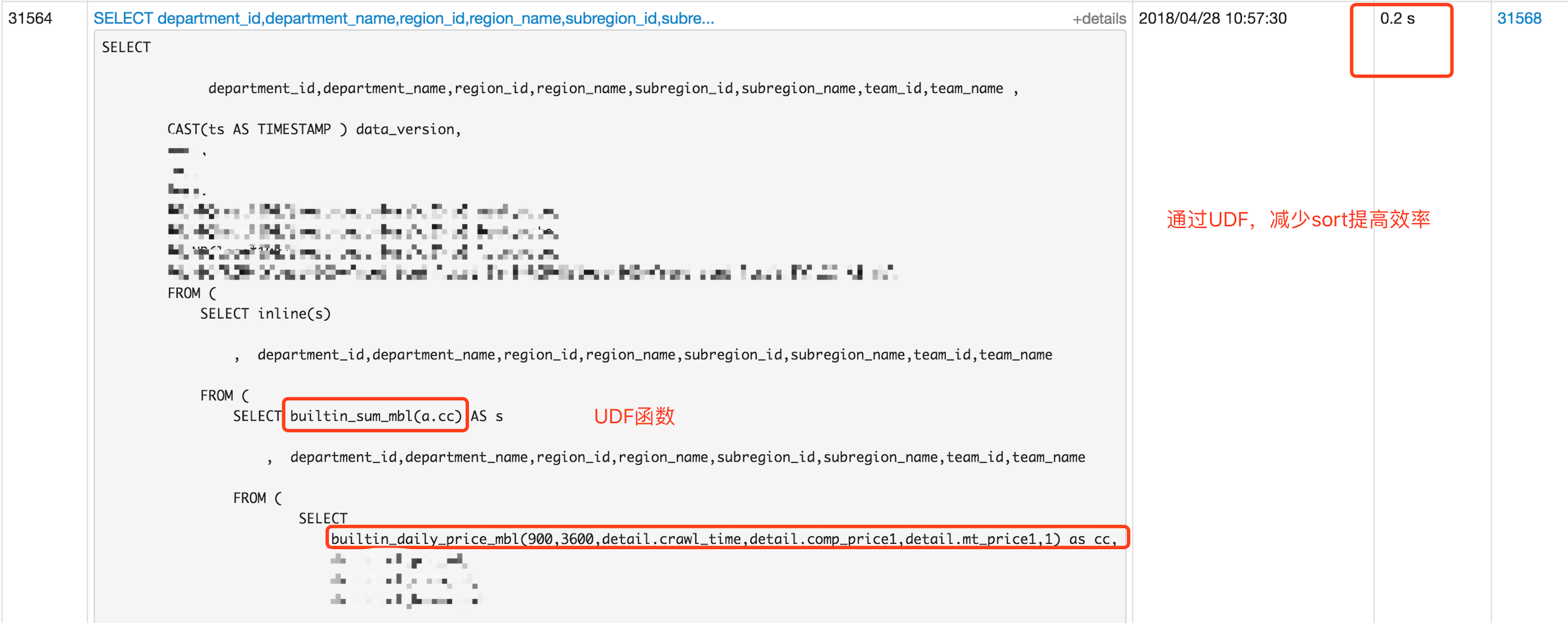
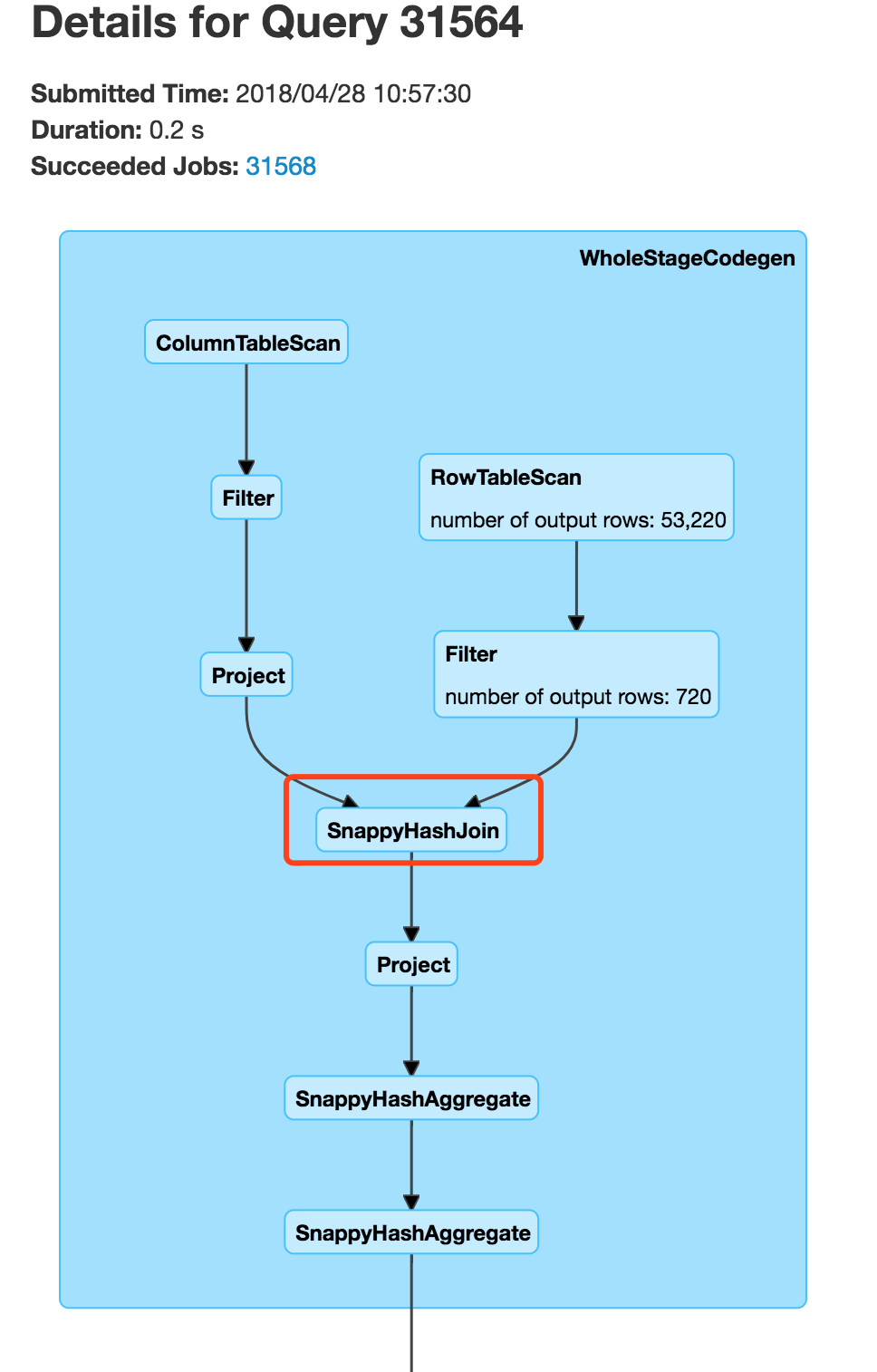
数据量在40亿,与其他事实表join的耗时在0.2s。
其执行计划完全是SnappyHashJoin,即本地操作且没有sort类操作:
五、总结
这篇文章中涉及了如何创建表,以及几个需要注意的点:
1 | 1、列表默认的partition数量为128,因此为了最大化的并行执行,需要根据集群规模设定每个表的partition数 |
之后的文章,我们会介绍如何利用监控界面在SnappyData中使用SQL进行优化,同时会涉及SQL优化的指导原则。